Digitale Editionen sind in den Geistes- und Kulturwissenschaften heute als State of the Art etabliert. Eine Vielzahl an Quellentypen aus verschiedenen Epochen wird inzwischen digital ediert. Dank ihrer nahezu unbegrenzten editorischen Möglichkeiten haben sich digitale Editionsverfahren gegenüber der reinen Druckpublikation als überlegen erwiesen (zur aktuellen Diskussion vgl. Driscoll/Pierazzo 2016). Der Umbruch von der gedruckten zur digitalen Edition bringt eine Fülle von Such- und Auswertungsmöglichkeiten mit sich und ermöglicht auch die Entwicklung und Ausdifferenzierung von semantischem Markup (zusammenfassend Sahle 2013). Die Text Encoding Initiative (TEI) konnte sich auf diesem Gebiet als maßgeblicher Standard etablieren.
Hier ein Beispiel einer TEI-XML-Textmodellierung:
<TEI> <text> <body> <div xml:id="Ms_germ_fol_841" next="#Ms_germ_fol_842"> <div type="session" n="1"> <p><pb facs="#f0011" n="7."/> erblicken wir einen großen Unterſchied zwi-<lb/> ſchen den entferntern u. nähern Planeten<lb/><note place="left"><hi rendition="#u">Zwei beſondere Planeten-Syſteme</hi><lb/></note>von der Soñe. <hi rendition="#u">Dies giebt zwei beſondre<lb/> Sÿſteme</hi>. Die Scheide machen die kleinern<lb/> Körper die ſich zwiſchen Mars u. Jupiter<lb/> bewegen, die ein ganz eignes Syſtem<lb/> bilden, von denen die Veſta als die<lb/><hi rendition="#u" hand="#pencil">größte</hi> <choice><sic>ungefahr</sic><corr resp="#CT">ungefähr</corr></choice> die <choice><abbr>Oberfl.</abbr><expan resp="#CT">Oberfläche</expan></choice> von Deutſch-<lb/> land hat. Sie haben eine translative Be-<lb/> wegung von Weſten nach Oſten, ſind ihrer<lb/> [...] </div> </div> </body> </text> </TEI> |
Abb. 1: XML-Seite aus dem deutschen Textarchiv (http://www.deutschestextarchiv.de/book/view/patzig_msgermfol841842_1828/?hl=welcher;p=11).
In den XML-Strukturen werden Text und Annotationen gemeinsam festgehalten (Inline-Annotation). Der Text bleibt beim o.a. einfachen Beispiel noch lesbar. Es ist aber offensichtlich, dass bei mehr Annotationsebenen die Komplexität stark zunimmt. Hinzu kommt, dass bei XML das sog. Containment gilt, d.h. verschiedene Annotationen dürfen sich nicht überschneiden. Dies führt bei komplexeren Annotationsszenarien zu Problemen bis hin zu dem Phänomen, dass nicht alle Annotationshierarchien in einer XML-Datei festgehalten werden können. Hintergrund ist die Eindimensionalität der in einer Textdatei festgehaltenen XML-Strukturen.
Eine multidimensionale Graphstruktur, die Texte flexibel verknüpfbar als Knoten und Kanten eines Netzwerks modelliert, eignet sich hier besser, da sie auch überlappende multidimensionale Annotationshierarchien abbilden kann (Kuczera 2020). Damit können verschiedene Annotationsebenen, z.B. Layout, Formatierung, Semantik, inhaltliche Erschließung und Kommentierung, gemeinsam modelliert und ausgewertet werden.
Beispiele für die Umsetzung digitaler graphbasierter Editionen stellen die Projekte “Die Sozinianischen Briefwechsel” (https://sozinianer.mni.thm.de/home) und “Das Buch der Briefe der Hildegard von Bingen. Genese – Struktur – Komposition” (https://liberepistolarum.mni.thm.de/home) des Antragstellers dar. Beide setzen auf die Kombination von Graphdatenbank (Neo4j) und graphbasierter Textmodellierung (Kuczera/Neill 2019) in Verbindung mit der TEI-Semantik und damit sowohl in der Datenmodellierung als auch in der editorischen Praxis auf Graphentechnologien (Kuczera 2020).
Thomas Efer hat ein solches Modell auch in seiner Dissertation beschrieben (Efer 2016):
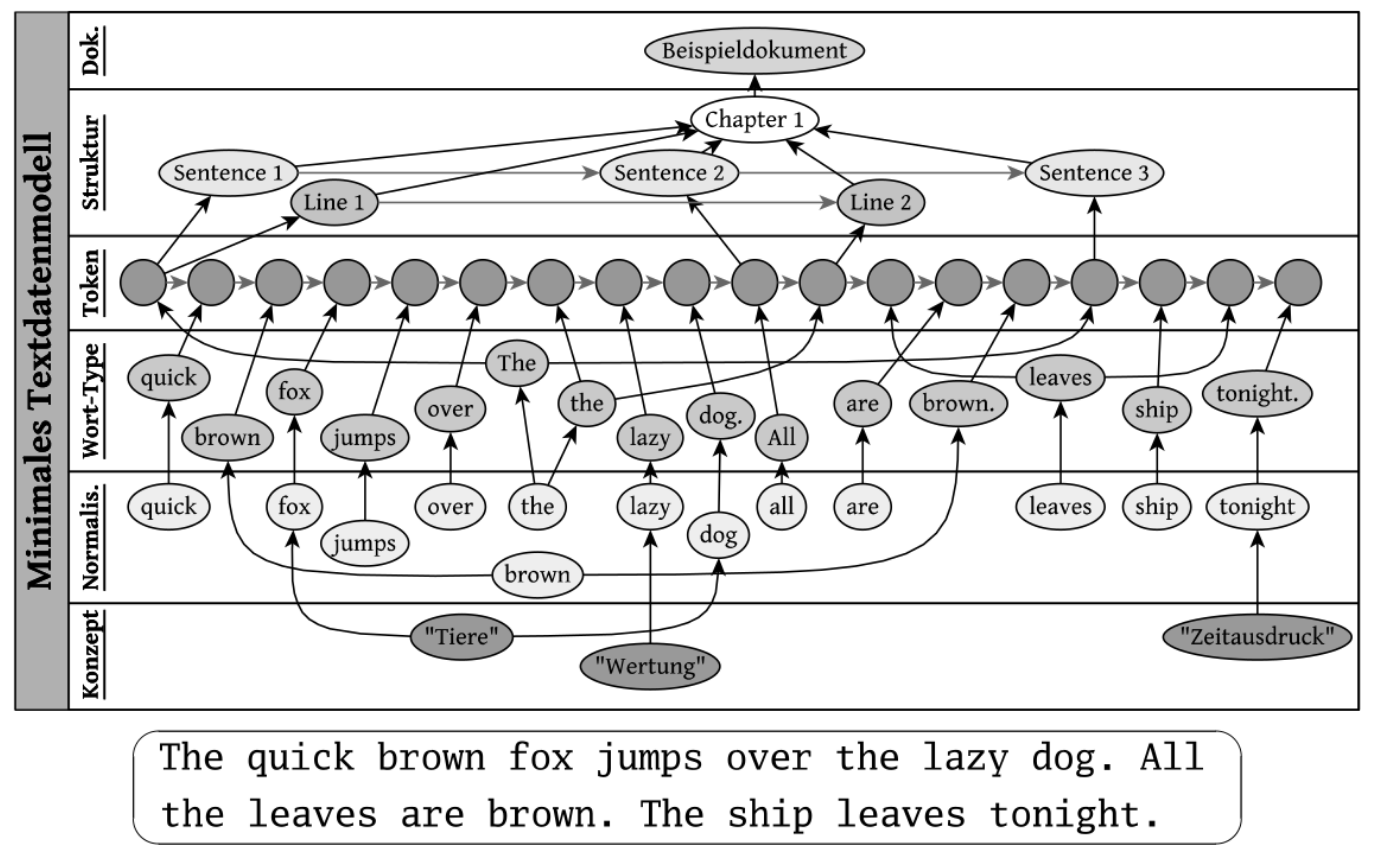
Abb. 2: Graphbasiertes Textmodell aus (Efer 2016), dort Abb. 3.1.
Efer endet in seiner Abbildung auf der Tokenebene. In unserem Anwendungsfall kommt noch eine weitere Ebene mit den einzelnen Zeichen in den Knoten hinzu, wie in der folgenden Abbildung zu sehen.
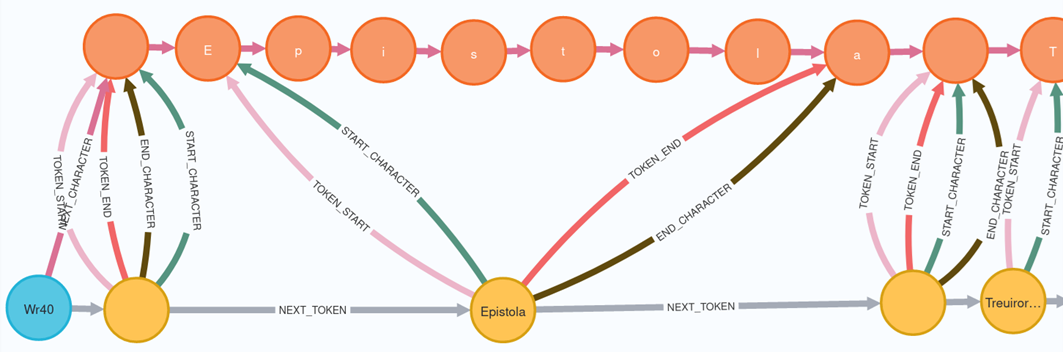
Abb. 3: Textmodell mit Token- und Characterebene.
Die Ebene mit den Einzelbuchstaben ist vor allem für die Annotation einzelner Buchstaben notwendig. Alle darüberliegenden Ebenen lassen sich jederzeit aus der Buchstabenebene berechnen. Aktuell ist es möglich, Ausgangstexte in TEI-XML, SPO oder Plaintext in Text-as-Graph umzuwandeln.
Der Vortrag zeigt die graphbasierten Editionen von SBW und Hildegard, die darauf abzielen, dem Herausgeber volle Flexibilität im Annotationsprozess zu geben und gleichzeitig die Interoperabilität mit der Semantik der TEI zu wahren.
Literatur:
Driscoll/Pierazzo 2016: Matthew James Driscoll/Elena Pierazzo (Hg.), Digital scholarly editing: Theories and practices, Cambridge 2016.
Efer 2016: Thomas Efer, Graphdatenbanken für die textorientierten e-Humanities. Augustusplatz 10, 04109 Leipzig, Abruf über Qucosa: urn:nbn:de:bsz:15-qucosa-219122, 2016
Gabler 2010: Hans Walter Gabler, Theorizing the Digital Scholarly Edition, in: Literature Compass 7/2 (2010), S. 43–56. https://doi.org/10.1111/j.1741-4113.2009.00675.x.
Hörnschemeyer 2017: Jörg Hörnschemeyer, Textgenetische Prozesse in Digitalen Editionen, Diss. Köln 2017.
Hotson/Wallnig 2019: Howard Hotson, Thomas Wallnig (Hg.), Reassembling the Republic of Letters in the Digital Age. Standards, Systems, Scholarship, Göttingen 2019.
Kuczera 2020: Andreas Kuczera, TEI Beyond XML – Digital Scholarly Editions as Provenance Knowledge Graphs, in: Tara Andrews, Franziska Diehr, Thomas Efer, Andreas Kuczera, Joris van Zundert (Hg.), Graph Technologies in the Humanities – Proceeding 2020, published at http://ceur-ws.org/Vol-3110/paper6.pdf.
Kuczera/Neill 2019: Andreas Kuczera, Iian Neill: The Codex – an Atlas of Relations. In: Die Modellierung des Zweifels – Schlüsselideen und -konzepte zur graphbasierten Modellierung von Unsicherheiten. Hg. von Andreas Kuczera / Thorsten Wübbena / Thomas Kollatz. Wolfenbüttel 2019. (= Zeitschrift für digitale Geisteswissenschaften / Sonderbände, 4) text/html Format. DOI: 10.17175/sb004_008
Sahle 2013: Patrick Sahle, Digitale Editionsformen. Zum Umgang mit der Überlieferung unter den Bedingungen des Medienwandels, Textbegriffe und Recodierung, 3 Bde., Norderstedt 2013 (Schriften des Instituts für Dokumentologie und Editorik, Bde. 7–9).
